1. 데이터 전처리
분석에 적합하게 데이터를 가공하는 작업
2. 데이터 전처리에 유용한 pandas 명령어
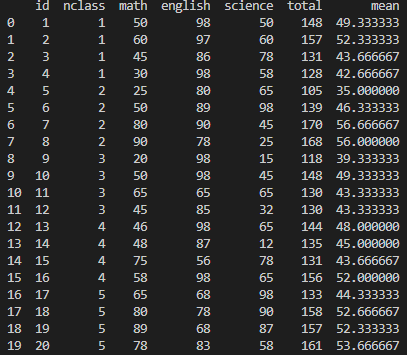
- 원본 데이터
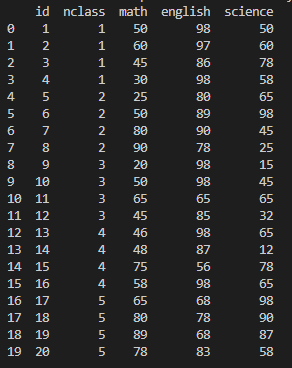
1. query() : 행 추출
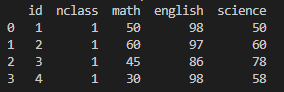
실행 명령어 : exam.query('nclass=1')
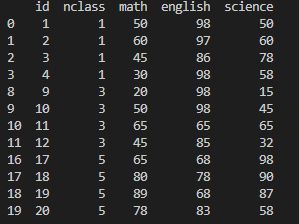
활용 명령어 : exam.query('nclass==1 | nclass==3 | nclass==5')
+ 추출한 행으로 데이터 만들기
test=exam.query('nclass==1 | nclass==3 | nclass==5')
test['math'].mean()

2. 데이터프레임명[] : 열 추출
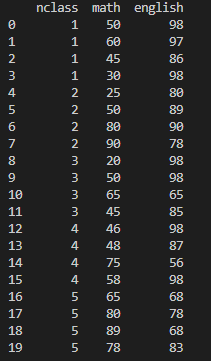
실행 명령어 : exam[['nclass','math','english']]
+ 특정 변수 제거하기
exam.drop(columns = 'math')
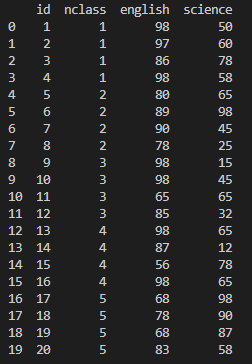
3. query() + 데이터프레임명[]
실행 명령어 : exam.query('nclass==1')['english']
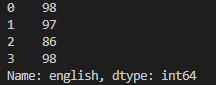
활용 명령어 : exam.query('math>=50')[['id','math']].head(5)
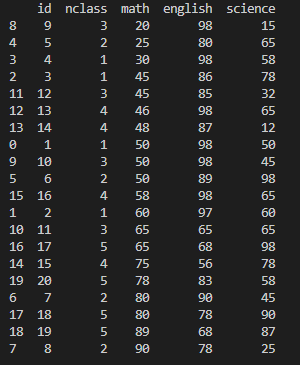
4. sort_values() : 정렬하기
실행 명령어 : exam.sort_values('math') #오름차순 정렬
실행 명령어 : exam.sort_values('math',ascending=False) #내림차순 정렬
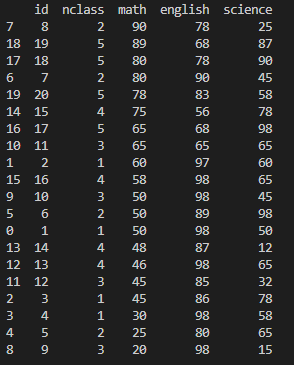
활용 명령어 : exam.sort_values(['nclass', 'math'], ascending=[True,False])
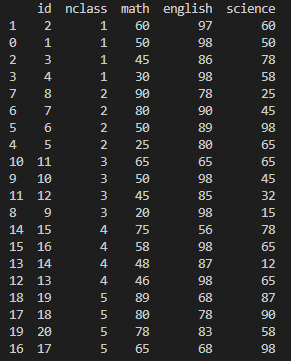
5. assign() : 파생변수 추가하기
실행 명령어 : exam.assign(total=exam['math']+exam['english'])
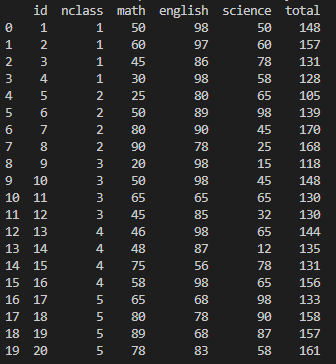
활용 명령어 : exam.assign(total=exam['math']+exam['english']).sort_values('total')
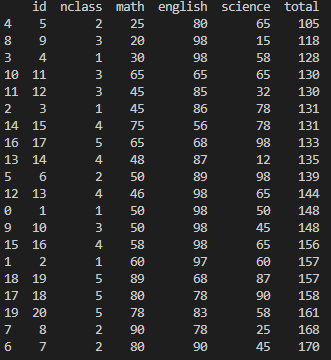
+ lambda를 활용하여 가독성 높이기
exam.assign(total = lambda x: x['math']+x['english'],
mean= lambda x: x['total']/3)
6. 집단별로 요약하기 : agg,groupby
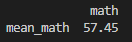
실행 명령어 : exam.agg(mean_math=('math', 'mean'))
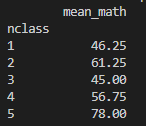
실행 명령어 : exam.groupby('nclass').agg(mean_math=('math', 'mean'))
+as_index=False 시 변수를 인덱스로 바꾸는 것을 막음
+ 요약 통계량 함수
|
mean()
|
평균
|
|
std()
|
표준편차
|
|
sum()
|
합계
|
|
median()
|
중앙값
|
|
min()
|
최소값
|
|
max()
|
최대값
|
|
count()
|
개수
|
7. 데이터 합치기 : merge(), concat()
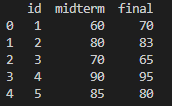
원본 데이터
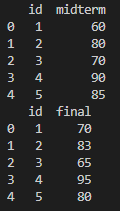
실행 명령어 : pd.merge(test1, test2, how='left', on='id')
#id를 기준으로 합침
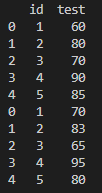
실행 명령어 : group = pd.concat([test1,test2])
'프로그래밍 > 파이썬' 카테고리의 다른 글
| 데이터 분석 - 파이썬으로 그래프 만들기(seaborn) (7) | 2023.01.12 |
|---|---|
| 데이터 분석 - 데이터 정제(결측치 이상치 제거, 대체) (3) | 2023.01.11 |
| [Python] 데이터 분석 기초(pandas, numpy, 파생변수) (7) | 2023.01.08 |
| [Python] 아나콘다 설치 및 파이썬, JupyterLab 이용하기 (3) | 2023.01.07 |
| [Django] 웹 프로그래밍 실습(5) - 로그인, 로그아웃, 회원가입 구현 (with alert 메시지) (0) | 2022.12.13 |