반응형
1. 사전 설치
#konlpy의 의존성 패키지
pip install jpype1
pip install konlpy
pip install wordcloud- konlpy는 자바가 설치되어 있어야 정상적으로 작동한다.
2. 텍스트 마이닝이란?
- 텍스트 마이닝 : 문자로 된 데이터에서 가치 있는 정보를 얻는 분석 기법
- 형태소 분석 : 문장을 구성하는 어절들이 어떤 품사인지 파악
3. 가장 많이 사용된 단어 알아보기
소스 코드(1)
#1. 연설문 불러오기
spe = open('speech_moon.txt', encoding='UTF-8').read()
#2. 불필요한 특수 문자, 한자, 공백 등 한글 아닌 문자 제거
import re
spe = re.sub('[^가-힣]',' ',spe)
#3. 명사 추출하기
import konlpy
han = konlpy.tag.Hannanum()
nouns = han.nouns(spe)
#4. 단어 빈도표 만들기
import pandas as pd
df_word = pd.DataFrame({'word':nouns})
df_word['count']=df_word['word'].str.len()
df_word=df_word.query('count>=2')
df_word.sort_values('count')
df_word = df_word.groupby('word',as_index=False).agg(n=('word','count'))
.sort_values('n',ascending=False)
#5. 단어 빈도 막대 그래프 만들기
top20 = df_word.head(20)
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams.update({'font.family':'Malgun Gothic'})
plt.rcParams.update({'figure.dpi':'120'})
plt.rcParams.update({'figure.figsize':[6.5,6]})
sns.barplot(data=top20, y='word', x='n')결과 사진

4. 워드 클라우드 만들기
소스 코드(1) + 소스 코드(2)
font='DoHyeon-Regular.ttf'
#단어와 빈도를 담은 딕셔너리 생성
dic_word = df_word.set_index('word').to_dict()['n']
#워드 클라우드 만들기
from wordcloud import WordCloud
wc=WordCloud(random_state=1234, #난수
font_path=font, #폰트 설정
width=400, # 가로
height=400, #세로
background_color='white') #배경색
import matplotlib.pyplot as plt
#워드 클라우드 생성
img_wordcloud=wc.generate_from_frequencies(dic_word)
plt.figure(figsize=(10,10)) #가로 세로 크기
plt.axis('off') #테두리 선 없애기
plt.imshow(img_wordcloud) #워드 클라우드 출력결과 사진
+ 워드 클라우드 모양 바꾸기
font='DoHyeon-Regular.ttf'
dic_word = df_word.set_index('word').to_dict()['n']
import PIL
#마스크로 사용할 png
icon=PIL.Image.open('cloud.png')
import numpy as np
#불러온 이미지 파일로 mask 만듦
img=PIL.Image.new('RGB', icon.size, (255,255,255))
img.paste(icon, icon)
img=np.array(img)
from wordcloud import WordCloud
wc=WordCloud(random_state=1234,
font_path=font,
width=400,
height=400,
background_color='white',
mask=img,
colormap='inferno')
import matplotlib.pyplot as plt
#워드 클라우드 생성
img_wordcloud=wc.generate_from_frequencies(dic_word)
plt.figure(figsize=(10,10)) #가로 세로 크기
plt.axis('off') #테두리 선 없애기
plt.imshow(img_wordcloud) #워드 클라우드 출력결과 사진

+ 워드 클라우드는 보기 예쁘지만, 정확한 분석을 위해서는
막대 그래프를 사용하는 것이 효과적이다.
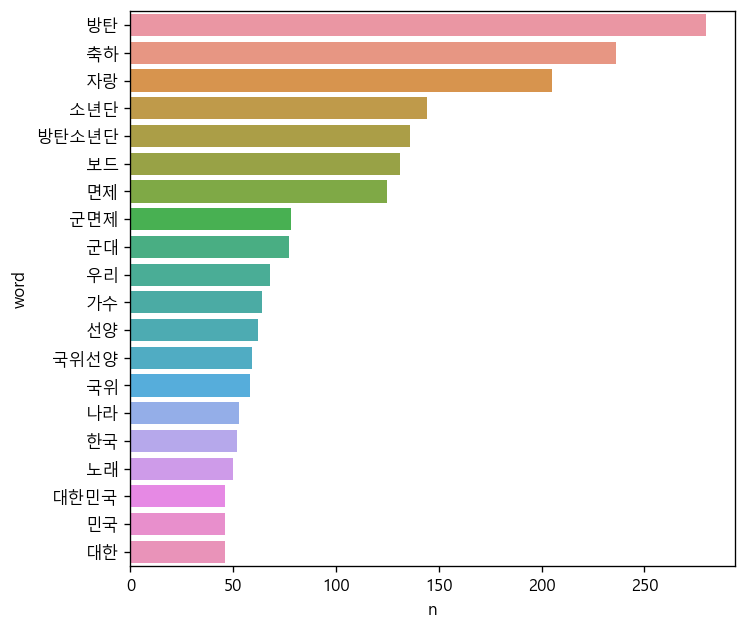
5. 기사 댓글 텍스트 마이닝
소스 코드
df=pd.read_csv('news_comment_BTS.csv',encoding='UTF-8')
#한글 제외하고 모두 제거
df['reply']=df['reply'].str.replace('[^가-힣]',' ',regex=True)
import konlpy
#띄어쓰기 오류있을 때도 형태소 잘 추출하는 형태소 분석기
kkma=konlpy.tag.Kkma()
nouns=df['reply'].apply(kkma.nouns)
#한 행에 한 단어만 들어가도록
nouns=nouns.explode()
#데이터프레임 생성 및 2번 이상의 빈도만 남김
df_word=pd.DataFrame({'word':nouns})
df_word['count']=df_word['word'].str.len()
df_word=df_word.query('count>=2')
#word를 기준으로 count하여 내림차순 정렬
df_word=df_word.groupby('word',as_index=False).agg(n=('word','count'))
.sort_values('n',ascending=False)
#상위 20개만 남김
top20=df_word.head(20)
import matplotlib.pyplot as plt
#크기 6.5 6으로 설정
plt.rcParams.update({'figure.figsize':[6.5,6]})
import seaborn as sns
sns.barplot(data=top20,y='word',x='n')결과 사진
'프로그래밍 > 파이썬' 카테고리의 다른 글
| 실전 데이터 분석 - 데이터 수집부터 시각화까지(with 후쿠오카) (7) | 2023.01.18 |
|---|---|
| 데이터 분석 - 지도 시각화(with folium) (7) | 2023.01.16 |
| 데이터 분석 - 실전 데이터 분석(한국복지패널 데이터) (5) | 2023.01.13 |
| 데이터 분석 - 파이썬으로 그래프 만들기(seaborn) (7) | 2023.01.12 |
| 데이터 분석 - 데이터 정제(결측치 이상치 제거, 대체) (3) | 2023.01.11 |