반응형
1. 시작에 앞서
요즘 데이터 분석 공부한 것을 활용도 하고,
2월 달에 갈 예정(?)인 후쿠오카에 대해 조사해보고 싶어
아침부터 열심히 코드를 작성했다.
전체적인 틀은 약 340개의 후쿠오카 관련 포스팅의
내용 중에 많이 작성된 명사는 무엇인지 시각화하는 것이다.
진행 단계 :
1. 웹 크롤링을 활용한 데이터 수집
2. 데이터 전처리 및 텍스트 마이닝
3. 데이터 시각화
2. import
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
import csv
import pandas as pd
import konlpy
from wordcloud import WordCloud
import seaborn as sns
import numpy as np
import pyperclip
import matplotlib.pyplot as plt
import PIL3. 데이터 수집
drive = webdriver.Chrome('chromedriver.exe')
lists_url = []
#크롤링할 url이 담겨있는 csv
data = pd.read_csv('naver.csv', encoding = "ISO-8859-1")
#사용하기 편하게 정리하여 lists_url에 저장
for i in data:
for j in range(len(data)):
lists_url.append(data[i][j])
content=""
for i in lists_url:
#selenium을 이용한 웹 크롤링
drive.get(i)
drive.switch_to.frame('mainFrame') #원하는 소스가 있는 프레임으로 변경
Text = ".se-component.se-text.se-l-default" # 내용 크롤링
contents=drive.find_elements_by_css_selector(Text)
#text값만 content에 저장
for x in contents:
content+=x.text
drive.implicitly_wait(10)
drive.implicitly_wait(10)- 크롤링할 url을 얻는 과정도 따로 존재하지만, 악용할 가능성이 있기에 따로 공개하지는 않겠다.
- 쉽게 설명해 포스팅마다 글자를 추출하여 "content"라는 값에 저장한다.
- 즉 343개의 포스팅에 대한 내용은 모두 "content"에 저장된다.
4. 데이터 전처리 및 텍스트 마이닝
#한글을 제외한 값 모두 공백으로 변환
content = re.sub('[^가-힣]',' ',content)
#konlpy의 Okt 사용
okt=konlpy.tag.Okt()
data=okt.nouns(content) #명사만 추출하여 data에 저장
df_word=pd.DataFrame({'word':data}) #word에 data값 저장
df_word['count']=df_word['word'].str.len() #각 단어의 반복횟수 count에 저장
df_word=df_word.query('count>=2') #반복횟수는 2 이상만 남김
df_word=df_word.query('word!="후쿠오카"') #word 값 중 후쿠오카는 제외
df_word.sort_values('count') #count를 기준으로 오름차순
df_word = df_word.groupby('word',as_index=False).agg(n=('word','count'))
.sort_values('n',ascending=False)아래와 같이 다양한 형태소 분석기 중에
"Okt"를 선택하여 명사를 추출했다.
이후 빈도를 기준으로 데이터 전처리를 진행하였다.

5. 텍스트 시각화
- 막대 그래프 형태로 출력
top20 = df_word.head(50) #상위 50개만 출력
#폰트 설정 및 그래프 크기 설정
plt.rcParams.update({'font.family':'Malgun Gothic'})
plt.rcParams.update({'figure.dpi':'120'})
plt.rcParams.update({'figure.figsize':[6.5,15]})
sns.barplot(data=top20, y='word', x='n')2. 워드 클라우드 형태로 출력
font='DoHyeon.ttf'
dic_word = df_word.set_index('word').to_dict()['n']
#마스크로 사용할 png
icon=PIL.Image.open('Cloud.png')
#불러온 이미지 파일로 mask 만듦
img=PIL.Image.new('RGB', icon.size, (255,255,255))
img.paste(icon, icon)
img=np.array(img)
wc=WordCloud(random_state=1234,
font_path=font,
width=400,
height=400,
background_color='white',
mask=img,
colormap='inferno')
#워드 클라우드 생성
img_wordcloud=wc.generate_from_frequencies(dic_word)
plt.figure(figsize=(10,10)) #가로 세로 크기
plt.axis('off') #테두리 선 없애기
plt.imshow(img_wordcloud) #워드 클라우드 출력
6. 출력 결과
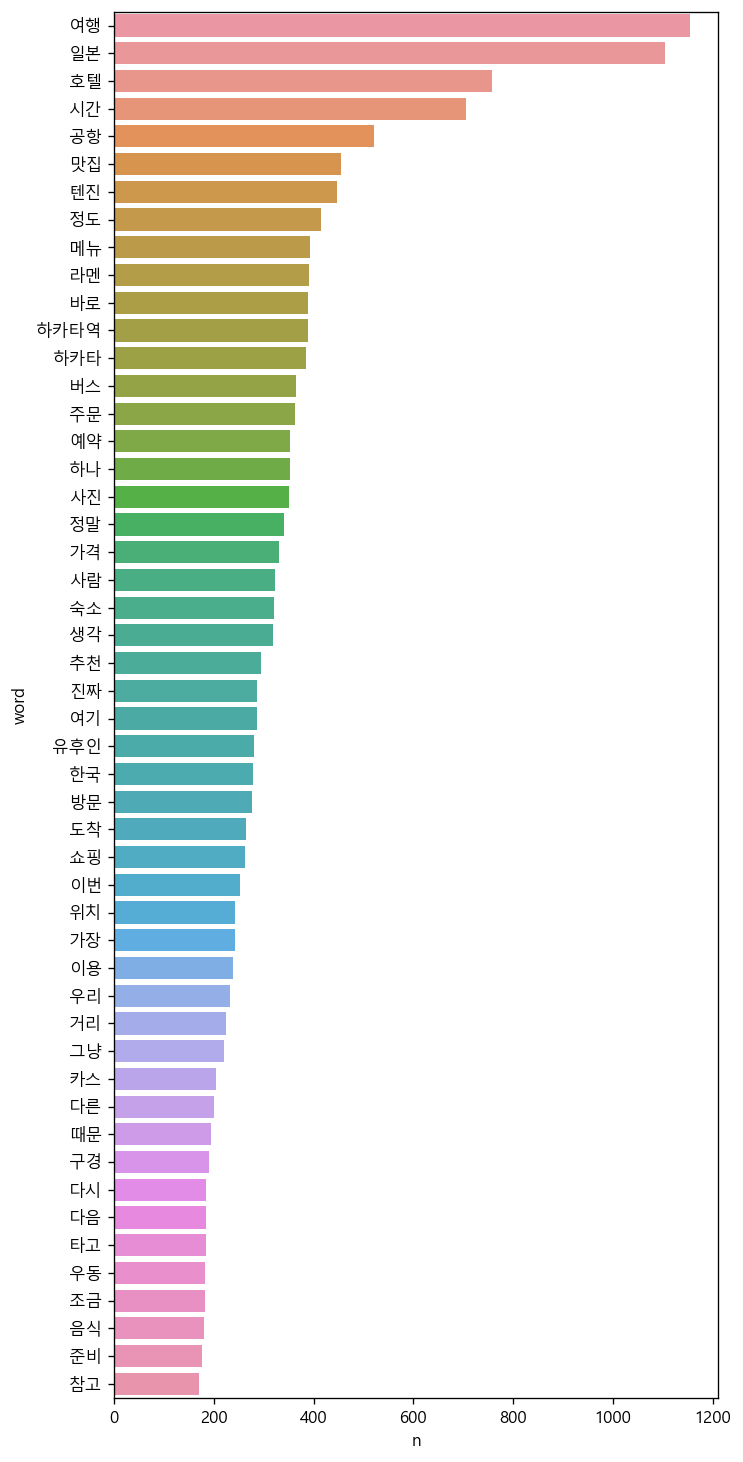

7. 결과 분석
장소 : 텐진, 하카타, 유후인, 모츠코우, 료칸, 커낼시티, 돈키호테, 대욕, 온천, 타워 등
음식관련 : 모츠나베, 모츠덴푸라, 야키니쿠, 니쿠이치 하타카점, 이치란라멘, 이자카야 등
엄청 유의미한 결과를 도출하지는 못하였다.
하지만 대강 한국 사람들이 어느 장소를 많이 방문하고
어느 음식을 많이 먹었구나 정도를 추측할 수 있었다.
이를 통해 한국인이 적은 지역을 가고 싶거나 색다른 음식을 먹고 싶다면
앞서 언급된 단어를 피해가면 된다.
또한 한국인이 많이 방문하여 인증된 장소나 먹거리를 원한다면
앞서 자주 언급된 단어를 찾아가면 될 듯하다.
'프로그래밍 > 파이썬' 카테고리의 다른 글
| 데이터 분석 - 의사결정 나무 모델 만들기 (5) | 2023.01.19 |
|---|---|
| 데이터 분석 - 통계 분석 기법을 이용한 가설 검정 (5) | 2023.01.18 |
| 데이터 분석 - 지도 시각화(with folium) (7) | 2023.01.16 |
| 데이터 분석 - 텍스트 마이닝(대통령 연설,기사 댓글) (6) | 2023.01.14 |
| 데이터 분석 - 실전 데이터 분석(한국복지패널 데이터) (5) | 2023.01.13 |