반응형
- 출처
빅데이터 연합 동아리 BITAmin : 네이버 카페
빅데이터 연합 동아리 비타민입니다.
cafe.naver.com
8기 멤버 문제이다.
개발 환경은 주피터 노트북이다.
- 문제1

1. iris의 species 열 값 분포를 확인하시오.
iris['species'].value_counts()
결과
setosa 50
versicolor 50
virginica 50
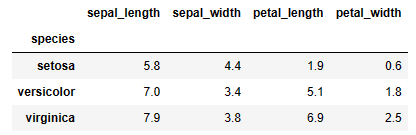
Name: species, dtype: int642. species 별로 각 변수의 최댓값을 구하시오.
iris.groupby('species').max()결과 :
3. iris의 species 열 값을 setosa는 1, 그 외의 값들은 0으로 변환하시오. (apply, lambda 사용)
iris['species']=iris['species'].apply(lambda x:1 if(x=="setosa") else 0)
iris결과 :

- 문제2

1. titanic에서 pclass, age, sibsp, fare, class 열만 뽑아 df에 저장하시오.
df=titanic[['pclass','age','sibsp','fare','class']]
df
결과

2. df의 열 별 결측치 개수를 구하시오.
df.isnull().sum()결과

3. df에 결측치가 있다면, 해당 열의 평균값으로 채우시오.
df.fillna(df.mean(), inplace=True)
df결과

4. survived.csv를 불러와 survived에 저장하시오.
survived=pd.read_csv('survived.csv')
survived결과

5. 기존에 생성한 df와 survived 데이터프레임을 병합해 df2에 저장하시오.
df2=pd.concat([df,survived],axis=1)
df2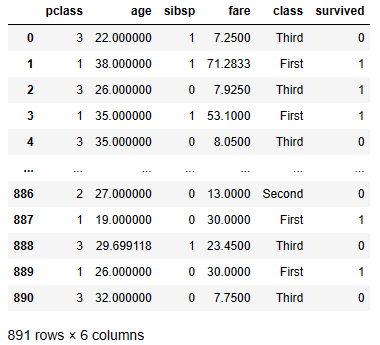
6. df2 데이터에서 각 class 별 생존율을 구하시오.
df2.groupby('class')['survived'].agg(lambda x:x.sum()/len(x))결과
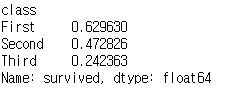
'프로그래밍 > 파이썬' 카테고리의 다른 글
| EDA - 2단계 : 실제 데이터 다루기 (3) (1) | 2023.07.29 |
|---|---|
| EDA - 2단계 : 실제 데이터 다루기 (2) (2) | 2023.07.27 |
| EDA - 1단계 : 데이터 다루기 - 변환 (1) | 2023.07.23 |
| EDA - 1단계 : 데이터 다루기 - 멀티인덱스, 반복 (1) | 2023.07.22 |
| EDA - 1단계 : 데이터 다루기 - 시간 (1) | 2023.07.20 |