반응형
- 출처
빅데이터 연합 동아리 BITAmin : 네이버 카페
빅데이터 연합 동아리 비타민입니다.
cafe.naver.com
10기 멤버 코테 내용이다.
주피터 노트북을 환경으로 했다.
- 문제1
1. midwest.csv를 불러와 midwest에 저장하고, 위에서부터 10행까지 출력하시오.
midwest=pd.read_csv("midwest.csv")
midwest.head(10)2.
- popwhite는 해당 지역의 아시아인 인구, poptotal은 해당 지역의 전체 인구를 나타냅니다.
- midwest 데이터에 '전체 인구 대비 아시아인 인구 백분율' 변수인 percent 열을 추가하세요.
midwest['percent']=(midwest['popwhite'])/midwest['poptotal']*100
midwest
3.
- percent 열의 값을 내림차순으로 정렬하세요.
midwest['percent'].sort_values(ascending=False)
midwest
4.
- percent를 아래의 분류 기준에 따라 새로운 변수를 추가해주시고, 각 분류에 해당하는 지역이 몇 개인지 확인해보시오.
- large: 0.9% 이상 / middle: 0.4~0.9% 미만 / small: 0.4% 미만
midwest['grade']=np.where(midwest['percent']>=0.9, 'large',
np.where(midwest['percent']>=0.4, 'middle', 'small'))
midwest.groupby('grade').agg(n=('grade','count'))
5.
- county가 'SCOTT'인 경우와 county가 'PIATT'인 경우의 poptotal 열의 평균을 각각 구해서 출력하세요.
- hint: query 함수와 mean 함수 사용
a=midwest.query("county=='SCOTT'")['poptotal'].mean()
b=midwest.query("county=='PIATT'")['poptotal'].mean()
print(a,b)- 문제2
1.
titanic에서 열별 결측치 여부를 확인하고, 결측치가 존재한다면 결측치를 해당 열의 평균값으로 채우세요.
titanic=sns.load_dataset('titanic')
titanic.isnull().sum()
titanic['age'].fillna(titanic['age'].mean(),inplace=True)
titanic
2.
titanic의 각 열에서 결측치가 아닌 데이터가 250개 이상이 되지 않는 경우, 이 열을 삭제한 후 df에 저장하세요.
df=titanic.dropna(axis=1, thresh=250)
df
3.
- 수치형 데이터의 열별 분포를 간략히 요약해 나타내세요.
- 평균, 최댓값, 사분위수 등
titanic.describe()
4.
titanic에서 sex와 pclass 별 생존율을 구하세요.
titanic.groupby(['sex', 'pclass'])['survived'].mean()
5.
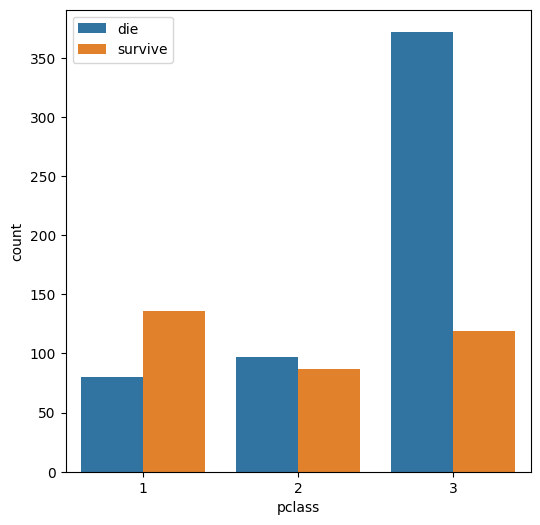
- pclass 별 사망과 생존 수치를 막대그래프로 나타내세요.
- sex 별 사망과 생존 수치를 막대그래프로 나타내세요.
- hint: countplot 함수 사용
fig,ax=plt.subplots(figsize=(6,6))
sns.countplot(data=titanic, x='pclass', hue='survived')
labels=['die','survive']
ax.legend(labels=labels)
plt.show()
6.
- titanic에서 age가 20살 이상이면 adult로, 20살 미만이면 child로 나타내는 label열을 추가하세요.
- hint: apply, lambda 함수 사용
titanic['label']=titanic.apply(lambda x:"adult" if x.age>=20 else "child", axis=1)
titanic
7.
- titanic에서 pclass, sex, age, sibsp, parch, class 열만 뽑은 후, parch의 값이 0인 행만 titanic1에 저장하세요.
- 이때 새롭게 만들어진 titanic1의 index는 0부터 다시 시작하도록 하세요.
- hint: loc 함수 사용
titanic1 = titanic.loc[titanic.parch==0,['pclass','sex','age','sibsp','parch','class']].reset_index(drop=True)
titanic1
'프로그래밍 > 파이썬' 카테고리의 다른 글
| EDA - 2단계 : 실제 데이터 다루기 (5) (2) | 2023.08.02 |
|---|---|
| EDA - 2단계 : 실제 데이터 다루기 (4) (1) | 2023.07.31 |
| EDA - 2단계 : 실제 데이터 다루기 (2) (2) | 2023.07.27 |
| EDA - 2단계 : 실제 데이터 다루기 (1) (3) | 2023.07.25 |
| EDA - 1단계 : 데이터 다루기 - 변환 (1) | 2023.07.23 |