전체 코드
주피터 노트북으로 작성한 내용을 html 파일로 저장한 것이다.
아래에서 다룰 내용을 모두 포함한 코드이다.
1. 라이브러리 import
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
train_df=pd.read_csv("train.csv")
test_df=pd.read_csv("test.csv")
submission = pd.read_csv("gender_submission.csv")
train_df.head()
#survivce : 생존여부, Pclass : 티켓 등급
#sibsp : 승선 중인 형제나 배우자의 수
#parch : 승선 중인 부모나 자녀의 수
#ticket : 티켓번호
#fare : 티켓요금
#cabin : 방 번호
#embarkder : 승선한 항구의 이름우선 EDA를 하기 전에 사용할 라이브러리를 import 해준다.
또한 제공받은 csv 파일도 각각 저장해준다.
이중 train_df 데이터를 head를 통해 위 5줄을 확인해본다.
이를 해석할 때 필요한 내용들을 주석으로 미리 정리해놓는다.
이는 캐글에서 정보를 얻을 수 있다.
2. EDA
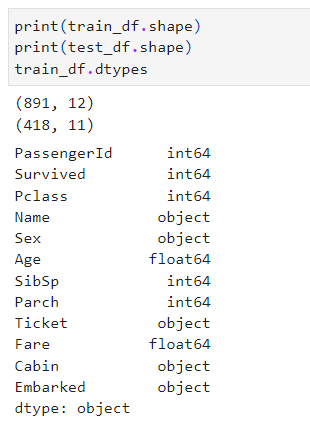
데이터의 행 열의 수, type, 통계값 등을 간단히 확인해보는 작업을 진행한다.
이는 데이터가 어떻게 구성되어있는지 확인하는 단계이다.
#카테고리 변수 확인하기
print(train_df["Sex"].value_counts())
print()
print(train_df["Embarked"].value_counts())
train_df["Cabin"].value_counts()
#결측치 확인
print(train_df.isnull().sum())
test_df.isnull().sum()이후에는 각 카테고리의 변수들은 어떻게 구성되어있는지 확인해준다.
또한 결측치는 얼마나, 어떤 카테고리가 존재하는지 확인한다.
3. 시각화
시각화는 목적 변수인 Survived에 관하여 진행한다.
- 목적 변수 : 기계학습의 교사 학습에 있어 예측하고 싶은 정보
- 설명 변수 : 기계학습의 교사 학습에 있어 예측에 사용하는 정보
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("ggplot")
#승선한 항구에 따른 생존
train_df[["Embarked","Survived","PassengerId"]]위 내용은 승선항, 생존 여부를 확인할 수 있다.
#데이터 수평화
embarked_df=train_df[["Embarked","Survived","PassengerId"]].dropna().groupby(["Embarked","Survived"]).count().unstack()
embarked_df
이를 보기 쉽게 결측치를 제거하고 group으로 묶어 확인한다.
추가로 unstack()을 사용해서 수평화를 진행한다.
#누적 막대
embarked_df.plot.bar(stacked=True)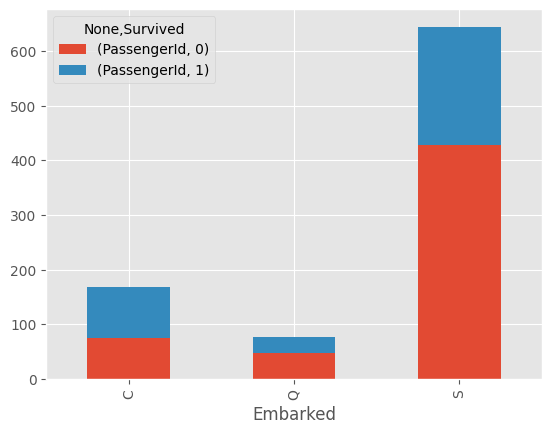
누적 막대 형태로 어느 승선항에서 얼마나 생존했는지 눈으로 쉽게 확인할 수 있다.
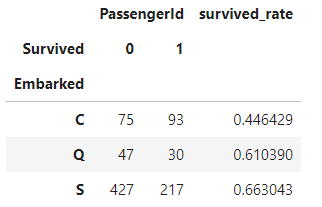
#사망률 수치화
embarked_df["survived_rate"]=embarked_df.iloc[:,0] / (embarked_df.iloc[:,0]+embarked_df.iloc[:,1])
embarked_df또한 위에서 수평화한 데이터를 iloc을 사용해서 생존율이 얼마있지 계산한다.
결과는 아래와 같다.
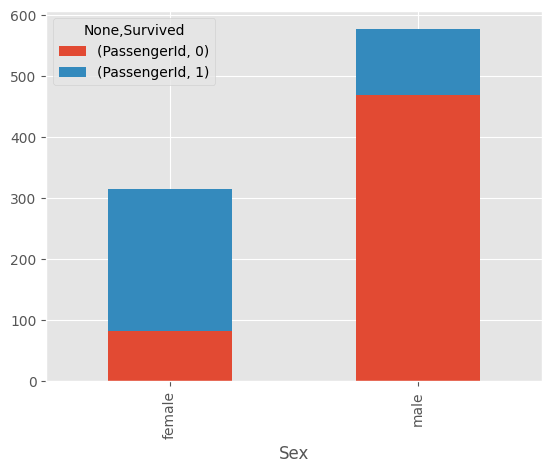
이러한 방식으로 성별 생존율을 시각화하면 아래와 같다.
이외에도 티켓 등급별, 연령별 생존율을 시각화하여 확인한다.
#원-핫 인코딩 : 1,0
train_df_corr = pd.get_dummies(train_df, columns=["Sex"], drop_first=True)
train_df_corr = pd.get_dummies(train_df_corr, columns=["Embarked"])
train_df_corr.head()추가로 원-핫 인코딩이라는 개념은 컴퓨터는 문자보다 숫자를 더욱 잘 이해하기에
원하는 값에는 1을, 그렇지 않은 경우에는 0으로 인코딩하는 방식이다.
이는 각 변수와 Survived 변수 간의 상관관계를 계산하기 위해 수치 데이터로 변환하는 과정이다.
즉 카테고리 변수를 더미 변수화한다고 한다.
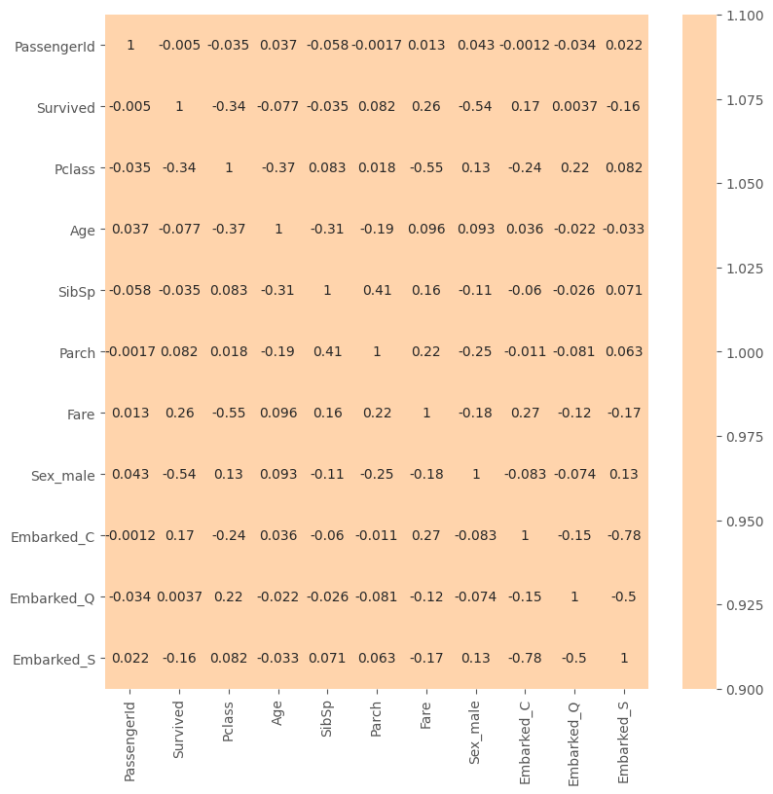
결과적으로 변수 간의 상관 관계를 상관 행렬로 작성하여 히트맵으로 시각화했다.
이를 통해 Survived와 가장 상관관계가 높은 것은 -0.54인 Sex_male이다.
이는 1이 남성, -1이 여성이기에 남성 생존율은 낮고, 여성 생존율은 높음을 의미한다.
2번째는 Pclass로 -0.34이다. 즉 티켓 등급이 높은 쪽의 생존율이 높았다.
이를 통해 어느 정도 유추는 할 수 있지만, 절대적인 지표는 아니다.
그렇기에 실제로 모델링을 하면서 결과를 통해 어느 변수가 중요한 지 알 수 있다.
4. 데이터 전처리
all_df = pd.concat([train_df,test_df], sort=False).reset_index(drop=True)concat을 사용해 학습, 테스트 데이터를 통합해준다.
Fare_mean=all_df[["Pclass", "Fare"]].groupby("Pclass").mean().reset_index()
Fare_mean.columns = ["Pclass","Fare_mean"]
#결측치 채우기
all_df = pd.merge(all_df, Fare_mean, on="Pclass", how="left")
all_df.loc[(all_df["Fare"].isnull()), "Fare"] = all_df["Fare_mean"]
all_df = all_df.drop("Fare_mean", axis=1)Fare의 결측치를 채우기 위해 Pclass별로 Fare의 평균값을 구한 후
빈 Fare값의 Pclass를 확인하여 해당 평균값으로 채워넣는다.
name_df = all_df["Name"].str.split("[,.]",2,expand=True)
name_df.columns=["family_name","honorific","name"]
name_df["family_name"]=name_df["family_name"].str.strip()
name_df["honorific"]=name_df["honorific"].str.strip()
name_df["name"]=name_df["name"].str.strip()
name_df이번엔 호칭별로 분석을 하기위해 Name 카테고리를 작업해준다.
,나 .를 기준으로 Name 값을 구분하여 name_df에 저장한다.
이후 공백을 모두 제거해준다.
추가로 호칭마다 인원수도 세주고, 연령 분포도 확인해준다.
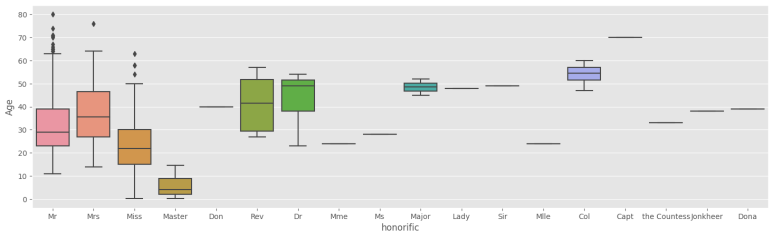
이는 호칭별 연령 분포에 대해 시각화한 것이다.
이를 통해 호칭에 따라 평균 연령에 차이가 있음을 확인할 수 있다.
이후 호칭에 따라 생존율에도 차이가 있는지 확인해본다.
#데이터 결합
train_df = pd.concat([train_df, name_df[0:len(train_df)].reset_index(drop=True)], axis=1)
test_df = pd.concat([test_df, name_df[len(train_df):].reset_index(drop=True)], axis=1)
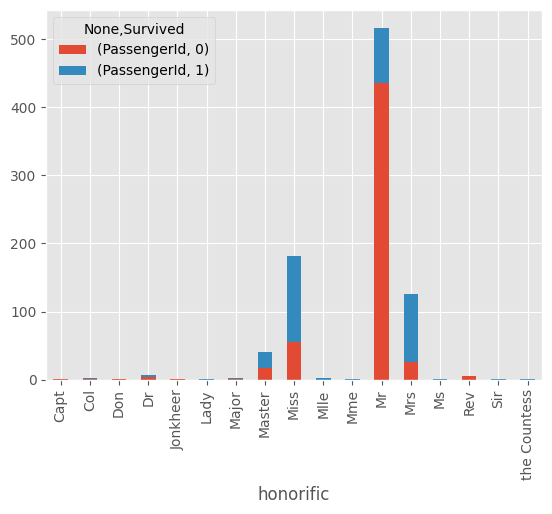
#호칭별 생존 여부 집계
honorific_df = train_df[["honorific", "Survived", "PassengerId"]].dropna().groupby(["honorific", "Survived"]).count().unstack()
honorific_df.plot.bar(stacked=True)결측치를 제외한 호칭, 생존율 데이터로 시각화한 것이 아래와 같다.
honorific_age_mean = all_df[["honorific","Age"]].groupby("honorific").mean().reset_index()
honorific_age_mean.columns=["honorific","honorific_Age"]
all_df = pd.merge(all_df, honorific_age_mean, on="honorific", how="left")
all_df.loc[(all_df["Age"].isnull()), "Age"] = all_df["honorific_Age"]
all_df = all_df.drop(["honorific_Age"], axis=1)
honorific_age_mean결측치를 호칭별 평균 연령으로 보완해준다.
추가로 가족 인원수, 홀로 승선했는지에 대한 여부, 불필요한 변수 삭제와 같은
작업을 진행할 것이다.
#가족 인원수 추가하기
all_df["family_num"] = all_df["Parch"] + all_df["SibSp"]
all_df["family_num"].value_counts()
#홀로 승선했는지 여부
all_df.loc[all_df["family_num"]==0, "alone"] = 1
all_df["alone"].fillna(0, inplace=True)
#불필요한 변수 제거
all_df = all_df.drop(["PassengerId", "Name", "family_name", "name", "Ticket", "Cabin"], axis=1)
all_df.head()이제는 카테고리 변수를 수치로 변환해야 한다.
이를 위해 object인 경우 categories 변수로 관리한다.
categories= all_df.columns[all_df.dtypes=="object"]
all_df.loc[~((all_df["honorific"]=="Mr") | (all_df["honorific"]=="Miss") | (all_df["honorific"]=="Mrs") | (all_df["honorific"]=="Master")),"honorific"]="other"
all_df.honorific.value_counts()
또한 Mr, Miss, Mrs, Master 이외의 호칭은 other로 통합해준다.
le = LabelEncoder()
le = le.fit(all_df["Sex"])
all_df["Sex"] = le.transform(all_df["Sex"])
for cat in categories:
le = LabelEncoder()
print(cat)
if all_df[cat].dtypes == "object":
le= le.fit(all_df[cat])
all_df[cat] = le.transform(all_df[cat])
all_df.head()문자열을 수치로 변환할 때 라벨 인코딩을 사용한다.
이전에는 더미 변수화 방법을 사용했었다.
4. 모델링(LightGBM) - 결정 트리 알고리즘
#랜덤 포레스트 - 결정 트리를 여러 개 만들어 합하는 방식 (앙상블)
#그레이디언트 부스팅 결정 트리 - 결정 트리를 순서대로 갱신
#특징 : 빠르고 결측치나 카테고리 변수가 포함된 상태에서도 모델 학습 가능
import lightgbm as lgb
#혿드 아웃 :학습, 검증 데이터 분할
#교차 검증 : 검증 데이터 사용해서 반복
#잭나이프법 : 전체 테스트 중 하나를 검증 데이터로, 나머지를 학습데이터로 데이터 수만큼 반복
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
X_train, X_valid, y_train, y_valid = train_test_split(train_X, train_Y, test_size=0.2)
#LightGBM용 데이터셋
categories = ["Embarked", "Pclass", "Sex", "honorific", "alone"]
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categories)
lgb_eval = lgb.Dataset(X_valid, y_valid, categorical_feature=categories, reference=lgb_train)
#하이퍼파라미터 - 2차분류
lgbm_params={
"objective":"binary",
"random_seed":1234
}
#모델 학습
model_lgb = lgb.train(lgbm_params, lgb_train, valid_sets=lgb_eval, num_boost_round=100, early_stopping_rounds=20, verbose_eval=10)
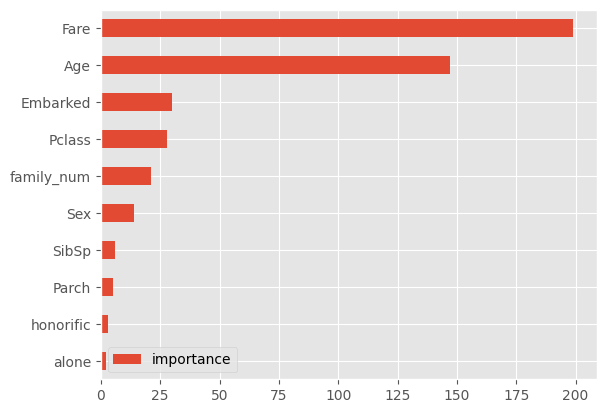
#변수의 중요도
importance = pd.DataFrame(model_lgb.feature_importance(), index=X_train.columns, columns=["importance"]).sort_values(by="importance", ascending=True)
importance.plot.barh()train_test_split을 통해 홀드 아웃을 진행해준다.
이를 lgb에 사용할 train, test 데이터로 구분하여 저장한다.
train 데이터셋을 이용해 학습하였을 때 가장 중요도가 높은 변수가 무엇인지 시각화한다.
#검증 데이터로 예측 정확도 확인
from sklearn.metrics import accuracy_score
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
accuracy_score(y_valid, np.round(y_pred)) #정확도검증 데이터를 사용해 예측 정확도를 확인해본다.
정확도는 accuracy_socre를 사용했다.
더 좋은 정확도를 얻기 위해 변화를 준다.
#하이퍼파라미터 변경
lgbm_params={
"objective" : "binary",
"max_bin" : 331,
"num_leaves" : 20,
"min_data_in_leaf" : 57,
"andom_seed" : 1234
}
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categories)
lgb_eval = lgb.Dataset(X_valid, y_valid, categorical_feature=categories, reference=lgb_train)
model_lgb = lgb.train(lgbm_params, lgb_train, valid_sets=lgb_eval, num_boost_round=100, early_stopping_rounds=20, verbose_eval=10)위와 같이 하이퍼파라미터를 변경하여 학습하여 정확도를 확인해보면
이전보다 소폭 상승된 것을 확인할 수 있다.
#교차 검증
folds=3
kf = KFold(n_splits=folds)
models=[]
for train_index, val_index in kf.split(train_X):
X_train = train_X.iloc[train_index]
X_valid = train_X.iloc[val_index]
y_train = train_Y.iloc[train_index]
y_valid = train_Y.iloc[val_index]
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categories)
lgb_eval = lgb.Dataset(X_valid, y_valid, categorical_feature=categories, reference=lgb_train)
model_lgb = lgb.train(lgbm_params, lgb_train, valid_sets=lgb_eval, num_boost_round=100, early_stopping_rounds=20, verbose_eval=10)
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
print(accuracy_score(y_valid, np.round(y_pred)))
models.append(model_lgb)마지막으로 교차 검증을 이용하여 학습한다.
3폴드 교차 검증을 진행했다.
마찬가지로 lgb에 맞는 데이터셋을 구현하고 이 데이터를 이용하여 train한다.
그리고 그 정확도를 확인한다.
#테스트 데이터 예측 결과 산출
preds=[]
for model in models:
pred=model.predict(test_X)
preds.append(pred)
#예측 결과 평균
preds_array = np.array(preds)
preds_mean = np.mean(preds_array, axis=0)
preds_int = (preds_mean>0.5).astype(int)
#파일 생성
submission["Survived"] = preds_int
submission
submission.to_csv("titanic_submit01.csv", index=False)마지막으로 test 데이터를 사용해 예측한 결과에 대한 파일을 만들어 캐글에 제출한다.
'프로그래밍 > 파이썬' 카테고리의 다른 글
| EDA - 3단계 : 캐글 스터디 마무리 (1) | 2023.10.31 |
|---|---|
| EDA - 3단계 : 캐글 스터디(1) (1) | 2023.09.15 |
| EDA - 3단계 : 캐글 스터디(with TAVE 12기) (1) | 2023.09.10 |
| EDA - 2단계 : 실제 데이터 다루기 (5) (2) | 2023.08.02 |
| EDA - 2단계 : 실제 데이터 다루기 (4) (1) | 2023.07.31 |