정렬
정렬은 원소들을 순서대로 배열하는 것을 말한다.
크기가 작은 순 혹은 큰 순으로 정렬하기도 한다.
정렬 알고리즘은 대략 3개의 그룹으로 나뉜다.
-기본 정렬 - 빅 세타 n^2
- 선택 정렬
- 버블 정렬
- 삽입 정렬
- 고급 정렬 - 빅 세타 nlogn
- 병합 정렬
- 퀵 정렬
- 힙 정렬
- 셸 정렬
- 특수 정렬 - 빅 세타 n
- 계수 정렬
- 기수 정렬
- 버킷 정렬
기본 정렬
- 선택 정렬
리스트의 가장 큰 원소를 찾아 리스트의 맨 끝자리 원소와 자리를 바꾸고,
정렬된 맨 오른쪽 부분은 제외한 상태로 반복하여 최종적으로 리스트를 오름차순 정렬하는 방법이다.

출처 : 쉽게 배우는 자료구조 with 파이썬

출처 : 쉽게 배우는 자료구조 with 파이썬
파이썬으로는 위와 같이 구현할 수 있다.
두 수를 비교하는 작업을 몇 번 하는지가 수행시간을 결정하기에
빅 세타의 n^2이라는 것을 알 수 있다.
2. 버블 정렬
가장 큰 원소를 오른쪽으로 정렬하지만, 왼쪽부터 한 칸씩 이동하며
근접한 값과 비교해 정렬하는 방식으로 진행한다.
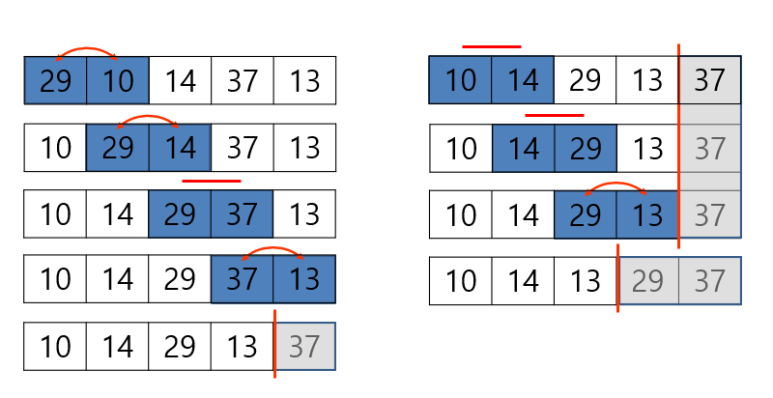
출처 : 쉽게 배우는 자료구조 with 파이썬
주변의 이웃한 값들과 계속해서 비교한다.
그렇기에 일반적으로 리스트의 크기가 커질수록 선택 정렬과의 수행 시간 차이가 늘어난다.

출처 : 쉽게 배우는 자료구조 with 파이썬
파이썬으로 구현한 코드이다.
마찬가지로 (n-1)+(n-1) + ... + 2 + 1 = 빅 세타의 n^2을 따른다.
3. 삽입 정렬
정렬되지 않은 리스트의 크기를 n부터 시작하여 하나씩 줄여가고,
정렬된 리스트의 크기를 1에서 시작하여 하나씩 늘린다.
즉 이미 정렬된 리스트에 원소를 계속해 삽입하며 정렬하는 방식이다.
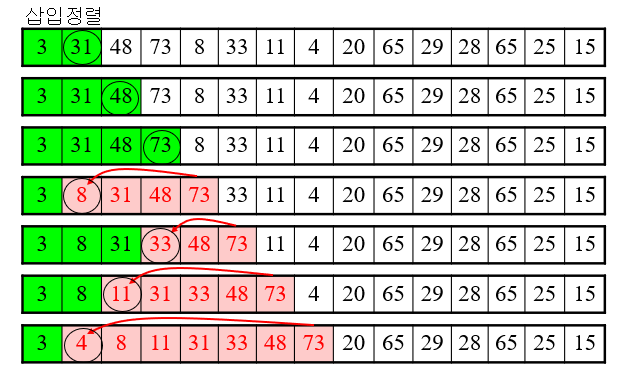
출처 : 쉽게 배우는 자료구조 with 파이썬

출처 : 쉽게 배우는 자료구조 with 파이썬
파이썬으로 구현한 코드이다.
A[i]은 기준이 되는 값, A[loc]는 정렬된 리스트의 마지막 값을 의미한다.
while문을 통해 정렬된 리스트 중에 기준 값보다 큰 값의 위치를 조정해준다.
계속해서 A[i]보다 큰 값들의 위치를 조정해주며 조건을 만족하지 않을 때까지 반복한다.
최종적으로 A[i]의 위치를 찾아 삽입하게 된다.
고급 정렬
- 병합 정렬
주어진 배열을 이등분하여 각각 정렬한 상태로 병합하여 정렬하는 방식이다.
아래는 두 부분으로 나누어서 정렬을 마친 상태의 데이터로 시작한 것이다.

출처 : 쉽게 배우는 자료구조 with 파이썬

출처 : 쉽게 배우는 자료구조 with 파이썬
파이썬으로 구현한 코드이다.
맨 위에서의 p값은 시작값, r값은 마지막값, q는 중간값을 의미한다.
merge 함수로 시작값을 i에 중간값을 j에 저장한다.
tmp라는 전체 리스트 길이의 0으로 채워진 리스트를 만든다.
처음 while문을 만족한다는 것은 두 부분으로 나눈 리스트 모두 값이 하나라도 존재한다는 뜻이다.
그렇기에 두 리스트의 현재 값 중 더 작은 값을 tmp에 저장하는 방식으로 계속해서 진행한다.
두 번째나 세 번째를 만족한다는 것은 두 부분의 리스트 중 한 부분의 리스트만 남아
해당 리스트만 tmp에 추가하면 되기에 if, else문이 사라진 모습이다.
최종적으로 i는 초기값, t=0으로 시작하여 처음 A라는 리스트에
정렬된 tmp 값들을 채워넣어서 정렬된 A 리스트를 얻을 수 있다.
점점 갈수록 재귀적인 표현이 자주 나오고 복잡해져서 단번에 코드를 이해하기 어렵기 때문에
부분부분 끊어서 해석하고, 재귀가 반복되는 함수를 해석하는 것이 중요하다.
이외의 퀵, 힙, 셸 정렬은 다음 포스팅에서 다룰 예정이다.
'대학교' 카테고리의 다른 글
| 마이크로프로세서 - (10) 16비트 타이머/카운터 (2) | 2023.11.20 |
|---|---|
| 파이썬 - (6) 여러 가지 자료형 (1) | 2023.11.15 |
| 마이크로프로세서 - (9) 8비트 타이머/카운터 (1) | 2023.11.12 |
| 한국 근현대사 - (7) 6.25 전쟁 이후 (1) | 2023.11.08 |
| 데이터구조 - (6) 우선순위 큐:힙 (1) | 2023.11.08 |