반응형

1. 주의사항
- 이 포스팅은 단순히 딥러닝 기술인 순환 신경망을 이용하여 주가 예측을 하는 원리를 설명하고 있다.
그렇기에 완성품을 설명하는 것이 아닌 주가 예측의 기본을 설명하는 것으로, 참고만 하는 것을 추천한다.
2. 순환 신경망(RNN)
- 순환 신경망에서 뉴런을 셀이라고도 부르는데, 이전의 데이터를 통해 학습된 셸의 상태 정보가
다음 데이터를 이용하여 학습시킬 때 다시 사용된다는 의미다.
셀에서 만들어지는 상태 데이터를 은닉 상태라고 한다.
활성화 함수로 쌍곡탄젠트 함수를 사용하여 계산할 수 있다.
셀에서 사용하는 이전의 은닉 상태는 과거 문맥에 관한 정보를 가지고 있어서
앞으로 발생할 데이터를 예측하는 데 활용된다.
3. 장단기 기억(LSTM)
- 데이터들의 연관 정보를 파악하려면 기억을 더 길게 유지하여야 하는데 그것을 가능하게 한다.
LSTM은 은닉 상태와 더불어 셀 상태를 계산하는데, 셀 상태를 계산하려면 망각 게이트와 입력 게이트를 이용한다.
망각 게이트 : 이전 셀 상태에서 지울 정보를 학습시킬 용도
입력 게이트 : 새로운 데이터를 학습하는 용도
망각 게이트+입력 게이트 = 현재 셀 상태
즉 텐서플로에서 RNN, LSTM을 구현해두었기에, 개념만 이해한 후 사용하면 된다.
학습 과정에서 사용된 적이 없는 테스트용 데이터셋을 분리해야 과적합 현상을 방지할 수 있다.
4. 주가 예측 코드
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
import numpy as np
import matplotlib.pyplot as plt
import test
mk = test.MarketDB()
#데이터 가져오기
raw_df = mk.get_price('삼성전자', '2020-06-04', '2022-10-18')
window_size = 10
data_size = 5
def MinMaxScaler(data):
"""최솟값과 최댓값을 이용하여 0 ~ 1 값으로 변환"""
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
# 0으로 나누기 에러가 발생하지 않도록 매우 작은 값(1e-7)을 더해서 나눔
return numerator / (denominator + 1e-7)
dfx = raw_df[['open','high','low','volume', 'close']]
#가격 정보를 0~1 사잇값으로 변환
dfx = MinMaxScaler(dfx)
dfy = dfx[['close']]
x = dfx.values.tolist()
y = dfy.values.tolist()
data_x = []
data_y = []
for i in range(len(y) - window_size):
_x = x[i : i + window_size] # 다음 날 종가(i+windows_size)는 포함되지 않음
_y = y[i + window_size] # 다음 날 종가
data_x.append(_x)
data_y.append(_y)
print(_x, "->", _y)
#데이터 분리
train_size = int(len(data_y) * 0.7)
train_x = np.array(data_x[0 : train_size])
train_y = np.array(data_y[0 : train_size])
test_size = len(data_y) - train_size
test_x = np.array(data_x[train_size : len(data_x)])
test_y = np.array(data_y[train_size : len(data_y)])
# 모델 객체 생성
model = Sequential()
# (10,5) 입력 형태 가지는 LSTM층을 추가한다. 전체 개수는 10개이고, relu를 사용한다.
model.add(LSTM(units=10, activation='relu', return_sequences=True, input_shape=(window_size, data_size)))
# 입력값의 일부분을 선택해서 그 값을 0으로 치환하여 다음층으로 출력한다.
model.add(Dropout(0.1))
model.add(LSTM(units=10, activation='relu'))
model.add(Dropout(0.1))
#유닛이 하나인 출력층을 추가한다.
model.add(Dense(units=1))
model.summary()
#최적화 도구는 adam을 사용하고 손실 함수는 평균 제곱 오차(MSE)를 사용한다.
model.compile(optimizer='adam', loss='mean_squared_error')
#훈련용 데이터셋으로 모델을 학습시킨다. epochs는 전체 데이터셋에 대한 학습 횟수이고,
#batch_size는 한 번에 제공되는 훈련 데이터 개수다.
model.fit(train_x, train_y, epochs=60, batch_size=30)
#테스트 데이터셋을 이용하여 예측치 데이터셋을 생성한다.
pred_y = model.predict(test_x)
5. 주가 예측 결과
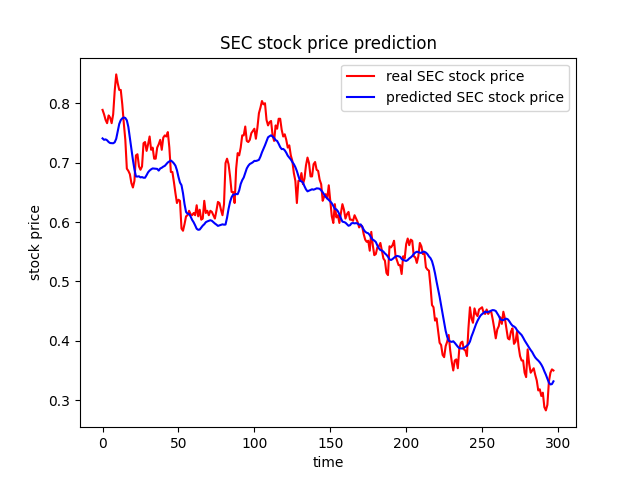
- 대강 이러한 추세로 실제와 예측을 그래프로 표현한 것이다.
엄청 단순한 코드이기에 실전에 쓸 수 없을 정도로 빈약하다.
그냥 이러한 방법도 있구나 정도로 접근하는 것이 좋다.
'경제 > 경제 정보' 카테고리의 다른 글
| 현재 경제 상황 분석 및 전망 (2) | 2023.06.15 |
|---|---|
| [경제] 매도대금담보대출 이란 ? (활용 방법 및 신용 등급) (1) | 2022.12.06 |
| [경제정보] 주식 주문 방식과 활용 (2) | 2022.10.17 |
| [경제정보] 국내 증권사 API별 특징 (Feat. 파이썬) (8) | 2022.10.14 |
| 투자 기초 용어 정리 (Feat. 월가의 퀀트 투자 바이블) (1) | 2022.10.11 |