1. 용어 정리
- 머신러닝 모델 : 함수 만들기와 비슷하다. 하지만 규칙을 컴퓨터가 데이터의 패턴을 찾아 정한다.
- 예측 변수 : 예측하는 데 활용하는 변수 또는 모델에 입력하는 값
- 타켓 변수 : 예측하고자 하는 변수 또는 모델이 출력하는 값
- 크로스 밸리데이션 : 데이터를 분할해 일부는 모델을 만들 때 사용하고 일부는 평가할 때 사용하는 방법
- 컨퓨전 매트릭스 : 예측한 값 중 맞은 경우와 틀린 경우의 빈도를 나타낸 값
- 의사결정나무 : 주어진 질문에 두 가지 선택지로 나뉘어 마지막에 결론을 얻는 구조
1단계 : 타켓 변수를 가장 잘 분리하는 예측 변수 선택
2단계 : 첫 번째 질문의 답변에 따라 데이터를 두 노드로 분할
3단계 : 노드에서 타켓 변수를 가장 잘 분리하는 예측 변수 선택
4단계 : 노드가 완벽하게 분리될 때까지 반복
특징
-> 노드마다 분할 횟수가 다름
-> 노드마다 선택되는 예측 변수가 다름
-> 어떤 예측 변수는 모델에서 탈락함
2. 소득 예측 의사결정나무 모델 만들기
1. import
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import tree
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import sklearn.metrics as metrics
import matplotlib.pyplot as plt2. 전처리하기
df=pd.read_csv('adult.csv')
#income:타켓변수(연소득)
df['income']=np.where(df['income']=='>50K','high','low')
df=df.drop(columns='fnlwgt') #불필요한 변수 제거
tar=df['income']
df=df.drop(columns='income')
df=pd.get_dummies(df) #income 제외하고 문자 타입 변수를 숫자 타입으로 변경
df['income']=tar
#데이터 분할하기
df_train,df_test = train_test_split(df,
test_size=0.3, #테스트 세트 비율
stratify=df['income'], #타켓 변수 비율 유지
random_state=1234) #난수 고정3. 의사결정나무 모델 만들기
Tree = tree.DecisionTreeClassifier(random_state=1234, #난수 고정
max_depth=3) #나무 깊이
train_x = df_train.drop(columns='income') #예측 변수
train_y = df_train['income'] #타켓 변수
model = Tree.fit(X=train_x, y=train_y) #모델 생성
plt.rcParams.update({'figure.figsize':[13,8],
'figure.dpi':'100'})4.모델 구조 시각화
tree.plot_tree(model,
feature_names=train_x.columns, #예측 변수명
proportion=True, #비율 표기
class_names=['high','low'], #타켓 변수 클래스, 알파벳순
filled=True, #색칠
rounded=True, #둥근 테두리
impurity=False, #불순도 표시
label="root", #label 표시 위치
fontsize=10) #글자 크기결과 사진
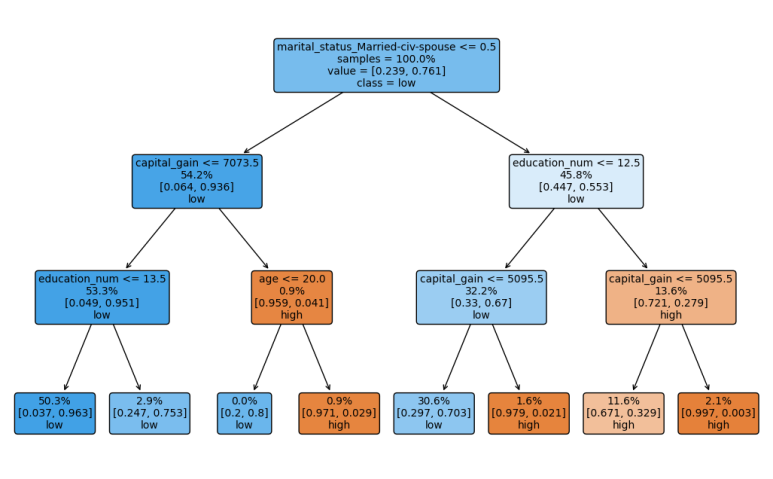
노드 값 설명(각 줄마다)
- 분리 기준
- 노드에 해당하는 관측치 비율 (전체 중에 얼마나 할당)
- 타겟 변수의 클래스별 비율 (high, low의 비율)
- 우세한 클래스 : 기준 0.5
+ 색 : high(주황), low(파랑)
5.모델 예측 및 성능 평가
test_x=df_test.drop(columns='income') #예측 변수
test_y=df_test['income'] #타켓 변수
df_test['pred'] = model.predict(test_x) #새 데이터의 타켓 변수값 예측
conf = confusion_matrix(y_true=df_test['income'], #실제값
y_pred=df_test['pred'], #예측값
labels=['high','low']) #클래스 배치 순서
#그래프 설정 초기화
plt.rcParams.update(plt.rcParamsDefault)
p=ConfusionMatrixDisplay(confusion_matrix=conf, #컨퓨전 매트릭스
display_labels=('high','low')) #타겟 변수 클래스명
p.plot(cmap='Blues') #컬러맵결과 사진
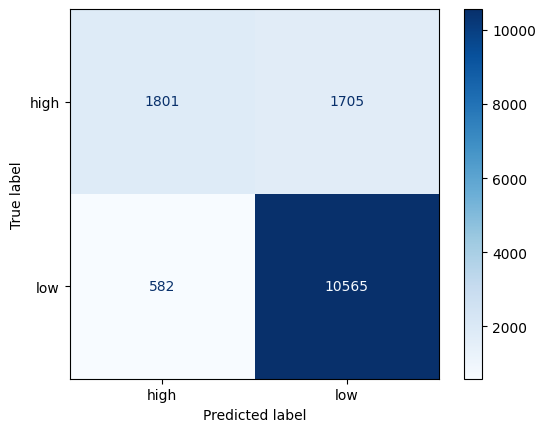
- 첫 번째 열
-> high 정답 -> high : 1801 (TP)
-> high 오답 -> low : 582 (FP)
- 두 번째 열
-> low 오답 -> high : 1705 (FN)
-> low 정답 -> low : 10565 (TN)
- 정확도 : 예측해서 맞춘 비율
metrics.accuracy_score(y_true=df_test['income'], #실제값
y_pred=df_test['pred']) #예측값
- 정밀도 : 관심 클래스를 예측해서 맞춘 비율
-> 관심 클래스가 분명할 때
-> 관심 클래스로 예측해서 틀릴 때 손실이 큰 경우
metrics.precision_score(y_true=df_test['income'], #실제값
y_pred=df_test['pred'], #예측값
pos_label='high') #관심 클래스
- 재현율 : 실제 데이터에서 관심 클래스를 찾아낸 비율
-> 관심 클래스를 최대한 많이 찾아내야 할 때
-> 관심 클래스를 놓칠 때 손실이 큰 경우
metrics.recall_score(y_true=df_test['income'], #실제값
y_pred=df_test['pred'], #예측값
pos_label='high') #관심 클래스
- F1 score : 정밀도와 재현율의 조화평균
-> 관심 클래스 예측 실패 손실과 놓칠 때 손실 둘 다 큰 경우
metrics.f1_score(y_true=df_test['income'], #실제값
y_pred=df_test['pred'], #예측값
pos_label='high') #관심 클래스'프로그래밍 > 파이썬' 카테고리의 다른 글
| 데이터 분석 - 데이터 추출 및 자료 구조 다루기 (2) | 2023.01.21 |
|---|---|
| [알고리즘] 백준 2644 파이썬 - 촌수계산 (1) | 2023.01.21 |
| 데이터 분석 - 통계 분석 기법을 이용한 가설 검정 (5) | 2023.01.18 |
| 실전 데이터 분석 - 데이터 수집부터 시각화까지(with 후쿠오카) (7) | 2023.01.18 |
| 데이터 분석 - 지도 시각화(with folium) (7) | 2023.01.16 |