반응형
1. 용어 정리
- 기술 통계 : 데이터를 요약해 설명하는 통계 분석 기법
- 추론 통계 : 단순히 숫자를 요약하는 것을 넘어 어떤 값이 발생할 확률을 계산하는 분석 기법
- 통계적 가설 검정 : 유의확률을 이용해 가설을 검정하는 방법
- 유의확률 : 실제로는 집단 간 차이가 없는데 우연히 차이가 있는 데이터가 추출될 확률
2. t검정 - 통계적 가설 검정
소스 코드
import pandas as pd
mp = pd.read_csv('mp.csv')
#각 집단의 데이터 준비
compact=mp.query('category=="compact"')['cty']
suv=mp.query('category=="suv"')['cty']
from scipy import stats
#집단 간 분산이 같다고 가정
stats.ttest_ind(compact,suv,equal_var=True)결과값으로 나온 p-value가 0.05미만이면 집단 간 차이가 통계적으로 유의하다고 볼 수 있다.
즉 우연이 아니다 라고 해석한다는 것이다.
3. 상관분석 - 통계적 가설 검정
소스 코드
import pandas as pd
eco = pd.read_csv('eco.csv')
#상관계수 구하기
eco[['unemploy','pce']].corr()
#유의확률 구하기
from scipy import stats
stats.pearsonr(eco['unemploy'], eco['pce'])출력 결과에서 두 번째 값이 0.05미만이면 상관관계가 통계적으로 유의하다고 볼 수 있다.
4. 상관행렬 히트맵 만들기
소스 코드
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
mt= pd.read_csv('mt.csv')
#상관행렬 만들기
mt_cor=mt.corr()
#소수점 둘째 자리까지 반올림
mt_cor=round(mt_cor,2)
plt.rcParams.update({'figure.dpi':'120',
'figure.figsize':[7.5,5.5]})
#행과 열의 수 만큼 0으로 채운 배열 생성
mask=np.zeros_like(mt_cor)
#오른쪽 위 대각 행렬의 값을 1로 바꿈
mask[np.triu_indices_from(mask)]=1
#첫 번째행과 마지막 열 제거
mask=mask[1:,:-1]
mt_cor=mt_cor.iloc[1:,:-1]
sns.heatmap(mt_cor,annot=True,cmap='RdBu', mask=mask, #상관계수, 컬러맵, mask
linewidths=6,vmax=1,vmin=-1,cbar_kws={"shrink":.5}) #경계 구분선, 최대값, 최소값, 범례 크기결과 사진
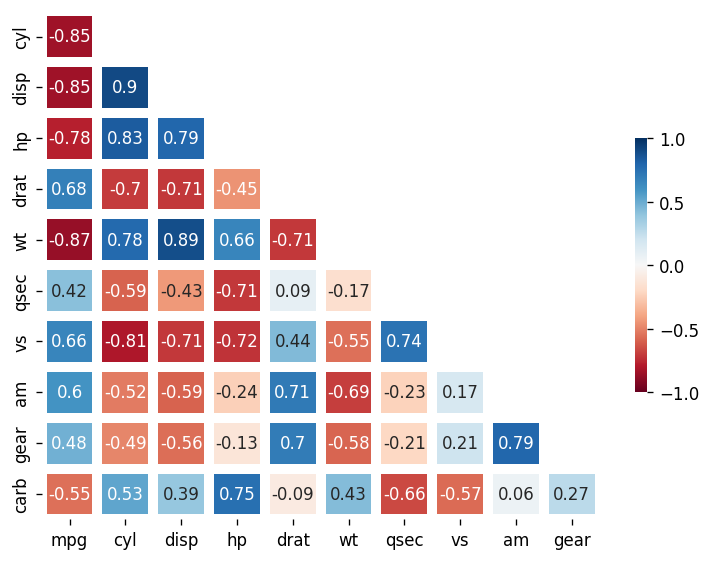
- 상관 계수라는 개념은 경제 공부를 하면서 처음 배웠다.
분산 투자를 하기 위해서는 각각 투자물에 대한 상관 계수를 인지하고,
한 방향으로 치우지지 않게 위험을 분산하는데 이 기법을 사용하였다.
- 이를 히트맵으로 표현하여 투자물 간의 상관계수를 관리하면
투자에도 도움이 될 듯하다.
5. 관련 자료
데이터 시각화 - 유형 및 특징(그래프, 히스토그램, 대시보드 등)
1. 데이터 시각화란? 말 그대로 데이터를 눈으로 볼 수 있게 여러 형태로 표현하는 것을 말한다. 즉 데이터 수치에서는 찾을 수 없던 새로운 인사이트를 얻을 수도 있으며, 데이터를 보는 사용자
maeseok.tistory.com
'프로그래밍 > 파이썬' 카테고리의 다른 글
| [알고리즘] 백준 2644 파이썬 - 촌수계산 (1) | 2023.01.21 |
|---|---|
| 데이터 분석 - 의사결정 나무 모델 만들기 (5) | 2023.01.19 |
| 실전 데이터 분석 - 데이터 수집부터 시각화까지(with 후쿠오카) (7) | 2023.01.18 |
| 데이터 분석 - 지도 시각화(with folium) (7) | 2023.01.16 |
| 데이터 분석 - 텍스트 마이닝(대통령 연설,기사 댓글) (6) | 2023.01.14 |